Unsupervised Learning and Gathering Data
Video
Motivation
OK, we now know how to:
- Format a existing dataset for SciKit Learn
- Train a SciKit Learn supervised estimator on the data
- Make predictions based on that training
However, this restricts us to a small portion of data - and formatting/inputting new data by hand is tiresome (all though, sometimes, the only way.)
Today we will be talking about:
- how to get non-preformatted data on your computer
- how to do simple categorization/validation/extraction with regular expressions
- how to get some insights with machine learning tools without a training dataset
Unsupervised Learning
Suppose we have some data without labels, and we don't want to bother going through and manually label a few hundred or thousand examples. Possibly we don't know what we want the labels to be - or we are just busy, or lazy.
You can get pretty decent insights with some of the other techniques SciKit Learn provides.
Dimensionality Reduction
One of the big problems with all this data is the number of different dimensions to the data, which makes it very hard to plot and visualize.
We could address that by ignoring all but a few dimensions and plotting them against each other - and that can be a good insight. However, many of the problems - such as our digits example - rely on multiple of the initial vectors to make a good guess:
import sklearn
from sklearn import datasets
from matplotlib import pyplot
digits = datasets.load_digits()
figure,axes = pyplot.subplots()
axes.hist2d(digits.data[:,12],digits.data[:,23])
figure
Well that sure wasn't helpful.
Dimensionality Reduction algorithms can help us visualize these interrelated relationships, and see data patterns that only show up when multiple axes are considered, without having to figure out how to plot 64-length vectors.
The example we will cover today - Principal Component Analysis - is a relatively simple and surprisingly effective idea; what if we rotate the data a bit before we discard axes, so that we are discarding dimensions that aren't contributing that much to the overall variance. This uses Singular Value Deompositions, and some other exciting mathematics, but we don't need to know it to use it. If you want to know it, there are many good explanations on the internet.
Let's ask PCA to reduce the dimensions to 2 more intelligently, without giving it our desired results:
from sklearn.decomposition import PCA
transformer = PCA(2)
d2_data = transformer.fit_transform(digits.data)
figure,axes = pyplot.subplots()
axes.scatter(d2_data[:,0],d2_data[:,1],s=3)
Well, that's certainly more information, and we can start to see some clusters and regions.
Let's see how well it represents our data:
figure,axes = pyplot.subplots()
scatter = axes.scatter(d2_data[:,0],d2_data[:,1],
s=5,alpha=.5,
c=digits.target,cmap=pyplot.cm.get_cmap("nipy_spectral",10)
)
figure.colorbar(scatter)
We can now see that - for relatively little effort - we have managed to pick out some of the groups!
It does a pretty good job of pickingout the 6s, 5s, and 0s - but the 3s, 8s, 7s, 2s, and 1s are a bit of a mess.
Plotting just the 8s and 5s, for example:
import numpy
pos_8_5s=numpy.logical_or(digits.target==8,digits.target ==5)
restricted_data = d2_data[pos_8_5s]
figure,axes = pyplot.subplots()
scatter = axes.scatter(restricted_data[:,0],restricted_data[:,1],alpha=.5,
c=digits.target[pos_8_5s],cmap=pyplot.cm.get_cmap("bwr",2)
)
figure.colorbar(scatter,ticks=[5,8])
Will see that it hasn't managed to separate them much at all - and is a good sign they might be hard to separate for our classifiers.
For just two dimensions, and not much work, though, these are pretty great results.
Clustering
Generating plots is all well and good, but you won't be able to do much with them except gain insight, or perform further analysis faster (but less accurately).
That's where the next unsupervised technique comes in Clustering. We will be using KMeans, a randomized algorithm. To get a repeatable result, we can set a internal seed.
from sklearn.cluster import KMeans
clusterer = KMeans(10, random_state=0)
clusters = clusterer.fit_predict(digits.data)
OK, but how do we know what the clusters mean? We didn't tell it any meanings.
One of the foundational principles of SciKit Learn is to give you access to the model internals if you want it. In this case, we're going to look at the cluster centers, the values that it thinks "most" represent each cluster.
figure, axeses = pyplot.subplots(10,figsize=(20,20))
for axes, center in zip(axeses,clusterer.cluster_centers_):
axes.imshow(center.reshape(8,8),cmap="Greys")
We can see that it successfully picked out most of the digits. However, it doesn't know what they mean to us, because we didn't tell it.
Classifying just these centers by hand, we can score the algorithm:
cluster_map = {
0:4,
1:3,
2:1,
3:2,
4:9,
5:0,
6:7,
7:6,
8:5,
9:8
}
classified_clusters = [cluster_map[i] for i in clusters]
(classified_clusters == digits.target).mean()
A few trials with different random seeds suggest this gets around 80% accuracy with no tuning, no pre-classifying, and nearly no work. Amazing!
Regular Expressions
Regular Expressions - RegEx for short - are an incredibly potent technology for describing, validating, transforming, and parsing strings. Within the language, it is possible to construct expressions which differentiate between any finite list of options, or perform any finite text extraction/replacement, often much shorter and faster than you could with traditional string methods.
They are also not always worth the trouble.

Fundamentally, a Regular Expression is a set of characters which define a space of valid patterns. The regular expression syntaxes differ slightly between most programs and programming languages - and, in some truly frustrating cases, within a program itself - so today we are going to focus on the Python syntax.
Your First RegEx
In Python, regular expressions are built by the re module from strings. Consider the following expression:
import re
word_re = re.compile("[Bb](an){2}a")
Let's give you a crash-course in RegEx string validation by breaking down what is happening with that string. Regular Expressions are controlled by the special characters . ^ $ * + ? { } [ ] \ | ( ). If you want to use those characters in a regular expression, you (usually) have to escape them with \ - for example, to match a ^, you can do \^. You can escape an entire string with the function re.escape.
[Bb]is a character set; it matches a characterBorb.(an)is a group; it matches precisely the charactersan, but groups them for use{2}repeats the previous character, character set, or group a precise number of times - in this case, 2.ais a character literal - not a special character - so it representsa.
This regular expression thus matches precisely the words Banana and banana.
We can also match Mississipi with M(iss){2}ipi, or more general Mississipi-likes with M(iss){2,}ipi (which would also match Missississipi and Mississississipi and so on.)
Let's say you wanted to find things wrapped in single-layer parentheses. (for deeper parentheses, you shouldn't use RegEx).
You can do that with a negative character set using ^:
paren_re = re.compile("\([^)]*\)")
paren_re.search("(1,2,3, this is in parens ) this is not")
Floating Points
Let's get a bit wilder, and talk about something more useful than counting the word Banana. Consider the following regular expression, and some examples:
floating_point_re = re.compile("^\s*-?\d+(\.\d*[1-9])?\s*$")
assert floating_point_re.search("254")
assert floating_point_re.search("-123")
assert not floating_point_re.search("-123.")
assert not floating_point_re.search("254.0")
assert floating_point_re.search("-123.56")
assert floating_point_re.search(" -123.56")
assert not floating_point_re.search("A Number -123.56")
assert not floating_point_re.search("1.234e4")
Let's break down this more complicated regex:
^at the start of the regular expression matches the start of the target string. Without this,a 123would match.
This is actually a bit redundant with the alternate callre.match- which already matches the start of strings (but not the end).
However, it is good communication to leave it in.\smatches any whitespace - tabs, spaces, and more esoteric forms. Without this,123would not match.*applies to the previous regex object, and matches0or more copies. Without this,123and123would both not match.-just means the character-(when outside of range expressions). Allows for negative numbers.?matches 0 or 1 - without it,-123would match, but123would not.\dis a shorthand for[0-9], itself a shorthand for[0123456789].*is the same -0or more of the previous character/group/character set.(\.\d*[1-9])is a group of characters, containing:\.refers to a decimal point character.; it is escaped because.is a special character.\d*is familiar - zero or more digits after the decimal place.[1-9]is a character set containing:- a character range
1-9, that is,
ASCII values between the digit1- in ASCII,49- and the value for the digit9- in ascii,57- are matched.
These values are123456789, and the group is equivalent to[123456789], but shorter.
Notably this excludes0.
- a character range
?is familiar, but note here that it refers to the group - either there is a decimal place and following characters, or neither.\s*means the same thing as well.$at the end of a regex means the end of string. Note that, if you want both^and$- the start and end of string - you can callre.fullmatchinstead ofre.search.
Taken together, this regular expression would check whether the input is a valid floating point number, with no extra leading or trailing 0s.
It can often be helpful to see a breakdown for an example regex, especially if you are unfamiliar with it. There are many good tools to help visualize, design, and test your regular expressions.
Capturing Groups
Let's say we wanted to extract all the floating point numbers from a given document.
Now we have a string that can identify floating point numbers anywhere; just remove the end and start:
import re
floating_point_re = re.compile("-?[1-9]\d*(\.\d*[1-9])?")
We can get all the values in the group with:
floating_point_re.findall("1 lorem2ipusm dolor 3 sit amet 4.5, 6.7 + -1.2")
However, this isn't particularly helpful for getting the floating point values. We can disable the capturing of the decimal group with a group option ?: for "non-capturing group":
import re
floating_point_re = re.compile("-?[1-9]\d*(?:\.\d*[1-9])?")
floating_point_re.findall("1 lorem2ipusm dolor 3 sit amet 4.5, 6.7 + -1.2")
And even define a group with the name value:
import re
floating_point_re = re.compile("(?P<value>-?[1-9]\d*(?:\.\d*[1-9])?)")
floating_point_re.findall("1 lorem2ipusm dolor 3 sit amet 4.5, 6.7 + -1.2")
Fractions
Naming your groups - especially when extracting multiple data points - is a great way to improve readability of your regular expression's intent, as well as helping you reliably match up the groups. However, it is one of the widest variations between implementations, so be wary when trying to use it in an unfamiliar situation.
For example:
fraction_re = re.compile("(?P<numerator>-?\d+)/(?P<denominator>\d+)")
fraction_re.findall("1/2,-1/3 blah -1.0/3.0 5/2.5")
Note that a simple regular expression - poorly designed - can pick up on information you may not want.
Lookahead/Lookbehind
Let's improve this expression to avoid decimals in the numerator or denominator with a negative lookahead/lookbehind:
fraction_re = re.compile("(?<!\.)(-?\d+)/(\d+)(?!\.)")
fraction_re.findall("1/2,-1/3 blah -1.0/3.0 5/2.5")
Now that's some fancy grouping.
Scientific Notation
Let's say we want to handle numbers in scientific notation, too.
Unfortunately, there are a few different scientific notations that people use - lower or uppercase E, lower or uppercase X, or even x10^.
We can use group options to get that:
scientific_notation_re = re.compile("-?\d\.\d+(?:x10\^|[eExX])-?\d+")
An important thing to note about group options is that this wouldn't work with the other order (?:[eExX]|x10\^); group options match the first matching option, and so would be captured by the single lowercase x instead before ever reaching the second option.
Extracting General Rationals
Let's talk about extracting more general numbers.
We can expect our rational numbers to be given in one of three forms:
- Decimal
- Scientific
- Fraction
Say we wanted to capture each. We could construct a regular expression with group options. However, one of the things that can help us is using our string-building skills to construct our more complicated regular expressions:
decimal_matcher = "-?\d+(?:\.\d+)?"
rational_matcher = "-?\d+/\d+"
scientific_notation_matcher = "-?\d\.\d+(?:x10\^|[eExX])-?\d+"
numeric_matchers = [
rational_matcher,
scientific_notation_matcher,
decimal_matcher,
]
numeric_group_string = "(" + "|".join(numeric_matchers)+")"
numeric_re = re.compile(numeric_group_string)
numeric_re.findall("3.0e5, 3/5,3.0x10^-5")
Building your longer regular expressions this way - and testing their subcomponents - is a great way to improve reliability, reusability, and to prevent regular-expression-based headaches.
Railroad Diagrams
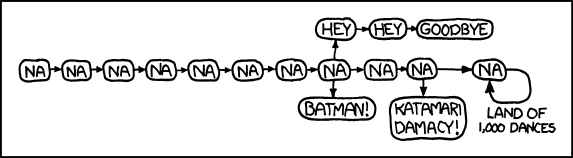
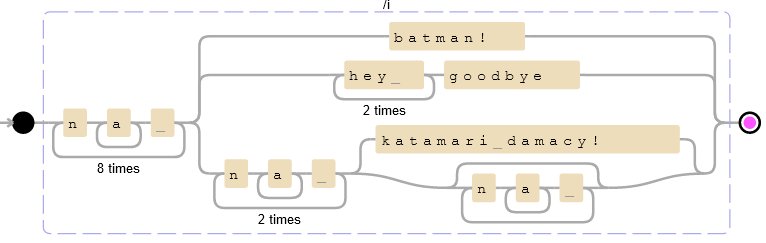
We could match the provided XKCD with:
na_re = re.compile("(na+ ){8}(batman!|(hey ){2}goodbye|(na+ ){2}(katamari damacy!|(na+ )*))",re.IGNORECASE)
assert na_re.fullmatch("Na na na na na na na na BATMAN!")
assert na_re.fullmatch("NAAAA na na na na na NA na na na KATAMARI DAMACY!")
These diagrams - called Railroad Diagrams - can be a useful way to visually represent, interpret, or check your regular expressions.
Many tools exist for constructing them, such as debuggex.
You may find the plots are cleaner once you make your groups non-capturing:
(?:na+ ){8}(?:batman!|(?:hey ){2}goodbye|(?:na+ ){2}(?:katamari damacy!|(?:na+ )*))
Getting Data
There are many open datasets out there, and we have discussed tools for extraction of tables from HTML. Here, I will briefly mention a few other methods you can look in to that we did not have time to discuss.
Data APIs
A variety of websites invite, or allow, analyzing the data they provide. This includes several popular social media sites, like Twitter and Reddit, each with their own API procedures, rules, and regulations.
Web Scraping
Beyond what websites help you with, Web Scraping is an excellent technology. I will not be getting in to it much, but the main libraries you will find useful for this - in Python - are:
requests, which can fetch website contents as Python stringsBeautifulSoup, which provides a simple interface for navigating and searching XML (and HTML) documents
Websites will write out what they want you to do - or more often not do - automatically in robots.txt files. These are, in general, guidelines and not a legal prohibition or permission - many people, including the big scapers like Google, ignore them at their own whims.
One thing to note is that it is responsible to rate limit your requests. You should wait - for example, with time.sleep - an amount of time depending on the server you are accessing, typically on the order of a second. This is not only polite but helps you not be flagged as a Denial of Service attack, which helps you maintain access to the website in question and keeps them from crashing under the load of your scraper.
Kaggle
Google runs a data analysis competition site called Kaggle, where people upload datasets to analyze. It also provides an interface to Python running on some google servers if you log in and register.
Assignment
Suppose you have some poorly formatted data, and you need to know a few things about the contents.
Specifically, for now, you need the publication year and the ISBN for each book.
You may assume the following unreasonable assumptions:
- Each book is on its own line, and each line refers to only one book.
- The year is given as 4 digits, and is within the last 220 years (i.e., starts
18,19, or20) - The year always comes before the ISBN, and is separated by at least two nonnumeric characters.
- The ISBNs provided are valid (i.e., don't worry about the checksum.)
- The ISBNs are numeric (i.e., they don't have the
Xchecksum digit.)
Write a Regular Expression which extracts - using groups - the year and ISBN. Use non-capturing groups for any other groups used in your Regular Expression.
Use your regular expression to extract all 48 date-ISBN pairs.
Write them, as two columns ISBN,Year, with headers, to a isbns.csv file, sorted by ISBN in ascending order. The ISBNs should be printed without any - characters - you will likely want to process them after extraction to replace '-' with '' (perhaps through a string method).
Upload your regular expression string, and isbns.csv, to Brightspace.
ISBNs
ISBNs were invented - like virtually all advancements in library science - by a dissatisfied mathematician. ISBNs are a 10-character string (which are often presented with dashes pseudorandomly distributed between the characters) consisting of 9 digits, followed by a checksum digit. The checksum digit can take any of 11 values - 0-10 or X (standing for 10) - and is computed mod 11 from the preceding 9 digits such that their sum (times their positions counted from the right) is 0:
\[\sum_{i=1}^{10}(11-i)x_i \equiv 0 \mod 11\]
For example, if we had the string:
isbn_candidate = "9971502100"
checksum = 0
for i,j in enumerate(isbn_candidate,start=1):
checksum+=(11-i)*int(j)
assert checksum%11 == 0
This has two remarkable properties which are easy to prove:
- Any change to any single digit results in an invalid ISBN.
- Any swap of any two (nonequal) digits results in an invalid ISBN.
ISBN13s are an abomination that squander the good work laid by ISBNs. They are:
- 13 numeric digits long
- Including one check-digit
- also sometimes contain hyphens
- do not provide transposition resistance for any two position pairs
They checksum via the superficially similar:
\[\sum_{i=1}^{6} 3x_{2i} + x_{2i+1} \equiv 0 \mod 10\]
Or in Python:
isbn_candidate = "9781470410483"
checksum = 0
for i,j in zip([1,3]*7,isbn_candidate):
checksum+=i*int(j)
assert checksum%10 == 0
You will need to capture both for this exercise, but you do not need to compute these checksums. You may if you wish, of course.